
Cinco analistas obtiveram os resultados (mmol de Ca), mostrados na tabela que se segue, para determinação de cálcio por um método volumétrico. As médias diferem significativamente em um nível de confiança de 95%?

Para saber se as médias diferem precisamos fazer a Análise de Variância (ANOVA). Pois temos que a hipótese nula H0 assume a forma:
H0 = μ1 = μ2 = μ3 = ... = μj
A hipótese alternativa Ha é que pelo menos dois dos μj são diferentes.
Assim a primeira coisa é inserir o dados no R.
> analista1 <- c(10.3,9.8,11.4)
> analista2 <- c(9.5,8.6,8.9)
> analista3 <- c(12.1,13.0,12.4)
> analista4 <- c(9.6,8.3,8.2)
> analista5 <- c(11.6,12.5,11.4)
> dados <- data.frame(analista1, analista2, analista3, analista4, analista5) # cria conjunto de dados
> dat <- stack(dados) # cria vector no formato pilha
> anova = aov(dat$values~dat$ind) # faz a anova
> summary(anova) # chama o resultado da anova
A hipótese alternativa Ha é que pelo menos dois dos μj são diferentes.
Assim a primeira coisa é inserir o dados no R.
> analista1 <- c(10.3,9.8,11.4)
> analista2 <- c(9.5,8.6,8.9)
> analista3 <- c(12.1,13.0,12.4)
> analista4 <- c(9.6,8.3,8.2)
> analista5 <- c(11.6,12.5,11.4)
> dados <- data.frame(analista1, analista2, analista3, analista4, analista5) # cria conjunto de dados
> dat <- stack(dados) # cria vector no formato pilha
> anova = aov(dat$values~dat$ind) # faz a anova
> summary(anova) # chama o resultado da anova
Df Sum Sq Mean Sq F value Pr(>F)
dat$ind 4 33.80 8.451 20.68 7.97e-05 ***
Residuals 10 4.09 0.409
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Como o resultado assim nos mostra, temos que o valor de F é igual a 20,68. Agora precisamos saber valor de F crítico (tabelado).
> qf(0.95, df1 = 4, df2 = 10) # f critico
Como resultado, o valor crítico de >F em um nível de confiança de 95% para 4 e 10 graus de liberdade é 3,48.
Uma vez que F é maior que 3,48, rejeitamos H0 em um nível de confiança de 95% e concluímos que existe diferença significativa entre os analistas.Lembrando que se F > Fcrítico rejeitamos H0 e passamos a aceitar a hipótese alternativa Ha, e se F < Fcrítico não podemos rejeitar H0.
Mas e agora, quem difere de quem? Para isso precisamos realizar a comparação entre as médias, pra isso realizaremos o Teste de Tukey.
> tk_teste <- TukeyHSD(anova)
> tk_teste
Tukey multiple comparisons of means
95% family-wise confidence level
Fit: aov(formula = dat$values ~ dat$ind)
$`dat$ind`
diff lwr upr p adj
analista2-analista1 -1.5000000 -3.2178202 0.21782021 0.0951550
analista3-analista1 2.0000000 0.2821798 3.71782021 0.0216352
analista4-analista1 -1.8000000 -3.5178202 -0.08217979 0.0391543
analista5-analista1 1.3333333 -0.3844869 3.05115354 0.1536633
analista3-analista2 3.5000000 1.7821798 5.21782021 0.0003966
analista4-analista2 -0.3000000 -2.0178202 1.41782021 0.9759180
analista5-analista2 2.8333333 1.1155131 4.55115354 0.0020822
analista4-analista3 -3.8000000 -5.5178202 -2.08217979 0.0002002
analista5-analista3 -0.6666667 -2.3844869 1.05115354 0.7098933
analista5-analista4 3.1333333 1.4155131 4.85115354 0.0009635
Pelo resultado do Teste de Tukey temos a comparação entre os analistas onde temos a diferença entre as médias e o valor de p. Para os valor de p < α podemos afirmar que as médias diferem ao nível de significância de 5% (α = 0,05). Quando p > α não é possível afirmar que as médias diferem.
O mesmo resultado pode ser expresso pelo gráfico do teste.
> plot(tk_teste)

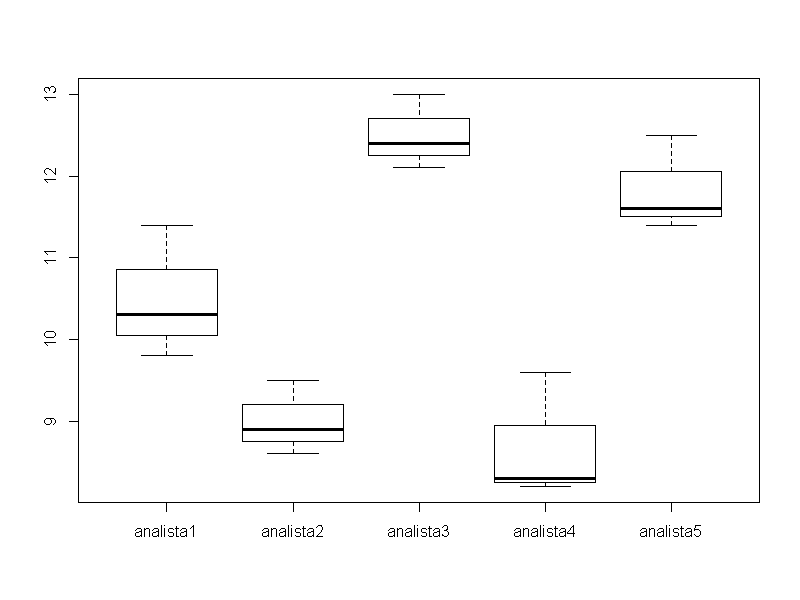
> boxplot(dados)
Vídeo demonstrativo:
Referências:
SKOOG, WEST, HOLLER, CROUCH. Fundamentos de Química Analítica. 8ed. 2006.
Parabéns! Muito obrigado pela ajuda!
ResponderExcluirOlá! Obrigado. Que bom que ajudou.
ExcluirSensacional! Obrigada por compartilhar esse conhecimento.
ResponderExcluirOlá Ana! Obrigado, caso encontre algum erro é só avisar.
ExcluirDemais!! Muito obrigado
ResponderExcluir